Lecture 1~3
<Lec 1 정리>
Machine Learning 이란?
- 일종의 소프트웨어 프로그램. 프로그램 자체가 data를 보고 학습해서 배워서 응용하는 능력을 갖는 프로그램.
ML은 크게 두가지로 나눌 수 있음.
Supervised Learning : 정해져 있는 data. Training set을 가지고 학습을 함.
Unsupervised Learning : Label 이 정해지지 않은 데이터를 가지고 학습. ex) word clustering, 구글 뉴스 등
Supervised Learning
예시로 이미지 라벨링, 이메일 스팸 필터, 성적 예측기 등이 있음. 기존의 자료가 있어야한다.
여기서 기존의 자료를 'Training Dataset' 이라고 함.
Supervised Learning 도 세가지 타입으로 나눌 수 있다.
Regression : 범위 내에서 결과값을 냄. ex) 공부한 시간에 따른 성적 예측하는 프로그램 0~100 사이의 결과 값 도출
Binary classification : 둘 중 하나로 분류하는 결과를 냄. ex) pass/nonpass
Multi-label classficiation : 여러개 레벨로 분류하는 결과. ex) A/B/C/D/F 로 분류
<Lec 2 정리>
Linear Regression 의 방법
H(x) = Wx + b 형태의 수식이 나올 것이라 가설을 세운다.
가설이 나타내는 선 중 가장 좋은 값이 무엇인지를 찾는다. -> Data 값과 가장 가까운 것이 좋은 값.
Training Data의 예시
1
1
2
2
3
3
어떤 Data가 있을 때 Linear한 선을 찾는 모델.
Cost Function (Lost Function)
가설을 세운 선과 Data의 거리를 측정하는 법. 가설과 실제가 얼마나 다른지 계산
= ( H(x) - y )^2

H(x)를 대입하여 계산해서, 가장 작은 값이 나오도록 W와 b를 구하는 것이 Linear Regression의 학습.
minimize cost(W,b)
<Lec 3 정리>
Const Function cost(W) 를 최소화하는 함수 찾기.
H(x) = Wx 로 간소화해서 가설 세우고, W가 0, 1, 2, ... 인 경우로 각각 data 대입하여 최소값 구하기.
예시) Training Data가 다음과 같을 경우
1
1
2
2
3
3
W=1 일때 cost(W) = 0
W=0 일때, cost(W) = 4.67
W=2 일때, cost(W) = 4.67
...
그래프를 그려 cost function 이 최소화되는 W값 찾기.
Gradient descent algortihm ( = 경사를 따라 내려가는 알고리즘)
=> 다음 알고리즘을 적용해 cost(W,b) 를 가장 최소화하는 W와 b의 값을 알 수 있다.
알고리즘의 작동법:
함수에서 경사도(기울기)를 구해 따라 움직이다 최종적으로 0에 도착. -> 항상 최저점에 도착한다는 것이 이 알고리즘의 장점.
아무 점에서나 시작 가능
W를 조금씩 바꾸며 cost를 줄임.
그 경사도를 계산해 반복하여 최소값 구함.
경사도 구하는 법
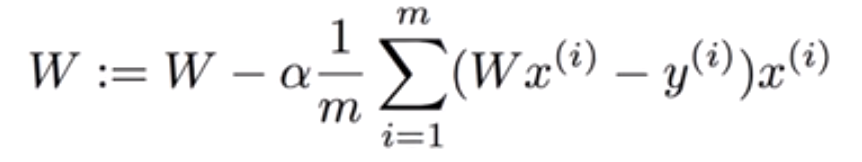
다음 수식으로 W 값을 변화시키면서 최저점 찾음.
Convex function : Gradient descent algorithm으로 그림을 그린 그래프. 밥 그릇 형태. 어디서 시작하든 항상 도착하는 점이 최저점이다.
Cost Function을 설계할 때 이 함수의 모양이 반드시 Convex Function이 되도록 해야한다!
필기 정리

출처
Last updated